Deploying a cluster is hard. Deploying a database cluster is harder. Deploying a database cluster repeatedly to the cloud is an unimaginable headache. Nowadays, IaC tools allows teams to automatically provision the complex intertwined cloud infrastructure in a deterministic manner. There can be multiple reasons why you would want to invest efforts into writing code for automating the deployment of a database cluster:
- Performance testing your applications' access patterns by pointing them to your database
- Documenting the custom configurations made while setting up the database
- Safely and quickly replicating environments for staging, testing, DR, etc
In this post, we'll look at deploying a MongoDB cluster to AWS with 1 primary (master) node and n secondary (data) nodes. We'll codify all our configurations with Terraform, shell scripts and Python scripts, to launch and bootstrap our cluster. This is the architecture diagram of the deployment:
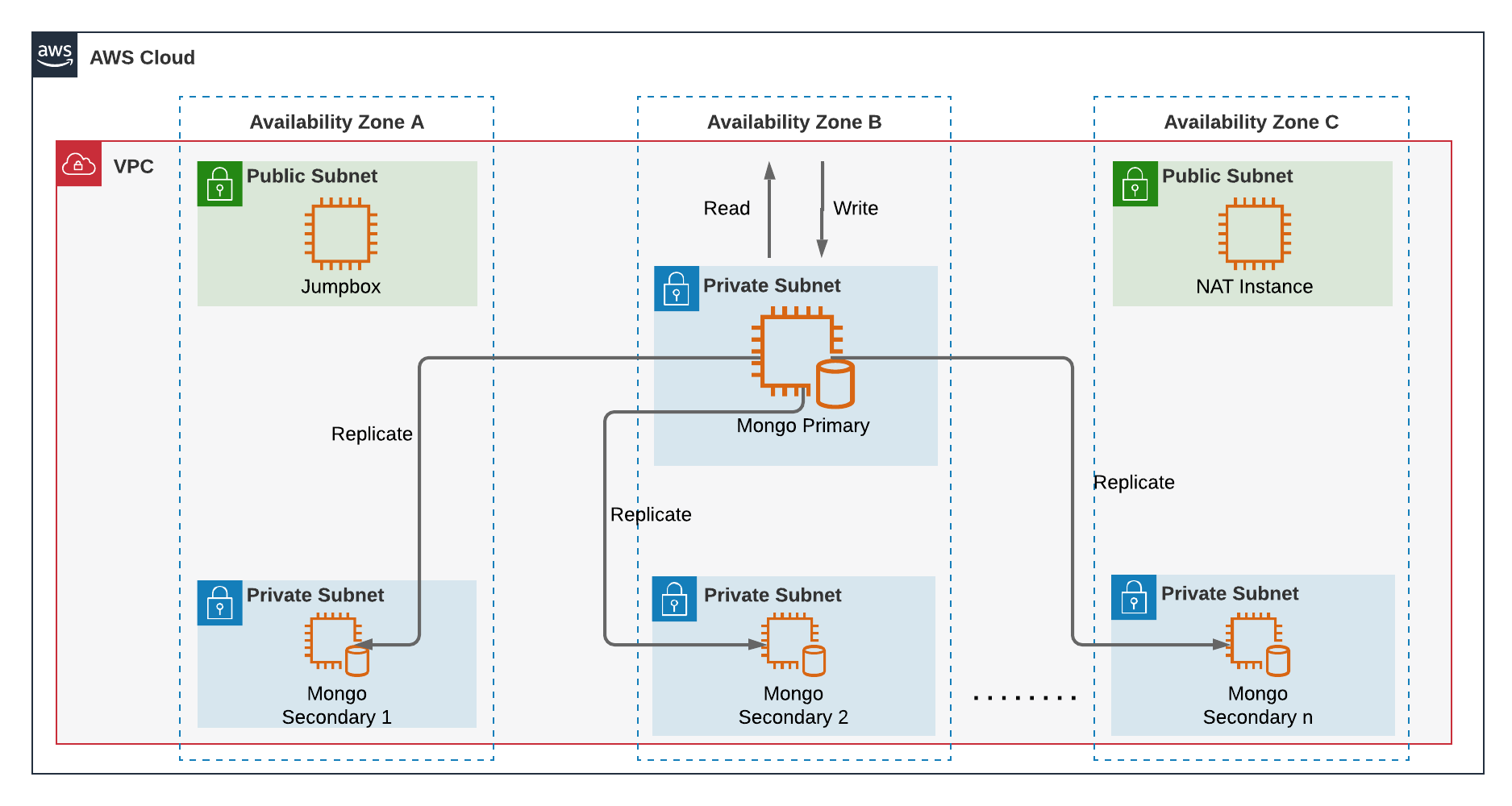 AWS Architecture Diagram for the MongoDB Cluster Deployment
AWS Architecture Diagram for the MongoDB Cluster Deployment
Let's go over the resources that are going to be created:
- A VPC to isolate and contain all the instances
- 3 Public subnets and 3 Private subnets spread across 3 Availability Zones
- A Bastion Host (or Jump Box) for accessing the instances in the private subnets from an external network
- A NAT instance to provide internet access to the instances in the private subnets. (Side tip: NAT Gateway costs stack up a lot quickly than you can anticipate. Go for a NAT instance if your workloads aren't critical)
All the source code is available at this GitHub repository. The code is structured as different Terraform modules such as VPC, JumpBox, MongoDB Cluster, etc. You can visit the repository for installation prerequisites and instructions on how to run the project. Here's a snippet of the main.tf file which utilizes all the Terraform modules:
module "vpc" {
source = "./vpc"
key_name = "${module.key_pair.key_name}"
vpc_name = "${var.vpc_name}"
}
module "key_pair" {
source = "./key_pair"
key_name = "mongo-key-pair"
public_key = "${file("~/.ssh/id_rsa.pub")}"
}
module "jumpbox" {
source = "./jumpbox"
key_name = "${module.key_pair.key_name}"
vpc_id = "${module.vpc.vpc_id}"
subnet_id = "${module.vpc.public_subnet_ids[1]}"
}
module "mongodb_cluster" {
source = "./mongodb_cluster"
key_name = "${module.key_pair.key_name}"
vpc_id = "${module.vpc.vpc_id}"
vpc_cidr_block = "${module.vpc.vpc_cidr_block}"
primary_node_type = "${var.primary_node_type}"
secondary_node_type = "${var.secondary_node_type}"
private_subnet_ids = "${module.vpc.private_subnet_ids}"
jumpbox_public_ip = "${module.jumpbox.jumpbox_public_ip}"
replica_set_name = "${var.replica_set_name}"
num_secondary_nodes = "${var.num_secondary_nodes}"
mongo_username = "${var.mongo_username}"
mongo_database = "${var.mongo_database}"
mongo_password = "${var.mongo_password}"
}
The MongoDB cluster module takes in a lot of configurable parameters which can be supplied by the terraform.tfvars file:
vpc_name = "mongo_vpc" replica_set_name = "mongoRs" num_secondary_nodes = 3 mongo_username = "admin" mongo_password = "mongo4pass" mongo_database = "admin" primary_node_type = "t2.micro" secondary_node_type = "t2.micro"
The MongoDB Cluster Module
We're going to deploy MongoDB v4.0 using the Ubuntu 18.04 AMI. This page from the official MongoDB documentation delineates steps to follow for installing MongoDB on Ubuntu. Just browsing through the insane number of steps involved or the confusing order of steps, you can imagine the dividend of scripting the commands rather than scampering through the documentation to figure out what worked the last time. Additionally, since this isn't a single node deployment, we need to deploy a replica set for MongoDB. Here's excellent documentation which expands on the replication features of MongoDB. And here's the documentation specifying the steps needed to deploy a ReplicaSet
The main.tf file for the MongoDB cluster module contains the code for creating the resources like EC2 instances, IAM policies, Security Groups, etc. Using Terraform's file provisioner, certain scripts and files (like the private key file needed to be shared by all the participating nodes) are uploaded to the instances while creating them. But wait, how can Terraform upload a file from your laptop to an instance launched in an AWS private subnet? Check out the nifty "bastion_host" parameter in the connection block:
provisioner "file" {
source = "${path.module}/keyFile"
destination = "/home/ubuntu/keyFile"
connection {
type = "ssh"
user = "ubuntu"
host = "${self.private_ip}"
agent = false
private_key = "${file("~/.ssh/id_rsa")}"
bastion_host = "${var.jumpbox_public_ip}"
bastion_user = "ec2-user"
}
}
Here's a snippet for creating the Secondary nodes. The "count" parameter (passed by the user) controls how many nodes to create. The instance is placed in any of the 3 private subnets in a round-robin manner.
resource "aws_instance" "mongo_secondary" {
count = "${var.num_secondary_nodes}"
ami = "${data.aws_ami.ubuntu_18_image.id}"
instance_type = "${var.secondary_node_type}"
key_name = "${var.key_name}"
subnet_id = "${var.private_subnet_ids[count.index % length(var.private_subnet_ids)]}"
user_data = "${data.template_file.userdata.rendered}"
vpc_security_group_ids = ["${aws_security_group.mongo_sg.id}"]
iam_instance_profile = "${aws_iam_instance_profile.mongo-instance-profile.name}"
root_block_device {
volume_type = "standard"
}
tags = {
Name = "Mongo-Secondary_${count.index + 1}"
Type = "secondary"
}
}
The userdata shell script contains the bulk of the configuration. It scans the AWS environment for the cluster members and configures each instance with the private IPs of other members. This is accomplished by using the EC2 Instance Metadata Service. Also, each instance has a Tag attached to it which helps to identify whether it's a Primary or Secondary node. Here are a few commands from the userdata shell script which creates MongoDB configuration and service files:
sed -i 's/127.0.0.1/0.0.0.0/g' /etc/mongod.conf
cat >> /etc/mongod.conf <<EOL
security:
keyFile: /opt/mongodb/keyFile
replication:
replSetName: ${replica_set_name}
EOL
chown ubuntu:ubuntu /etc/mongod.conf
cat >> /etc/systemd/system/mongod.service <<EOL
[Unit]
Description=High-performance, schema-free document-oriented database
After=network.target
[Service]
User=mongodb
ExecStart=/usr/bin/mongod --quiet --config /etc/mongod.conf
[Install]
WantedBy=multi-user.target
EOL
Go ahead and deploy the cluster in your AWS environment. Make sure you have a public-private keypair in the ~/.ssh directory. Use ssh-keygen to create the key files. Install Terraform and the AWS CLI. Create ~/.aws/credentials file to store your AWS Secret Key and Access Key locally for Terraform to use. I hope everything works great on the first try. If not, please feel free to reach out and I'll be more than happy to help!